Stable Diffusionとは?できることや活用例、利用する際の注意点を分かりやすく紹介!

Fotographer AI, Inc.
Latest Update :
September 1, 2023


YouTubeやInstagramの投稿をはじめ、日常生活の中で目にすることも多くなった画像生成AIですが、ひとえに「AI」といってもいくつか種類があります。
本記事では、その中でも代表的な画像生成AIの一つである「Stable Diffusion」について、基本的な内容や、利用用途・注意点、簡単な利用方法などを簡単にご紹介します。参考になれば幸いです。
「そもそも画像生成AIってなに?」という方はこちらの記事でより詳しく書いておりますので、合わせてご覧ください。
Stable Diffusionとは
Stable Diffusionとは、入力されたテキスト情報や画像データをもとにして画像を生成することができるAIの一つです。
2022年8月にStability AIから公開されたStable Diffuionですが、画像生成AIという言葉が世の中に広く知れ渡るようになった火付け役ともされています。
理由は非常にシンプルで、既にリリースされていた他の画像生成AIと比較して高いクオリティの画像を生成することができ、かつオープンソース(無料)で、誰でも利用することができたからです。
当時はすでに、Alphabet社(Google)によって開発された「Imagen」や、GPTで名高いOpenAIが発表していた「DALL・E」などの画像生成AIがありましたが、後発にもかかわらず画像生成AIにおける御三家として呼ばれているほど著名です。
Stable Diffusionと他の画像生成AIとの違い
そんな画像生成AIを代表するStable Diffusion。他のサービスとの違いについてご紹介します。
オープンソースなので無料で誰でも利用できる
1つ目は、無料で誰でも利用できる点です。
先に述べたように画像生成AIにはいくつか種類がありますが、Stable Diffusionが登場するまでは、利用する画像生成AIを利用すること自体に対して料金を支払う必要があったり、画像を生成できる回数に制限があったりするようなことがほとんどで、画像生成AIの知名度も爆発的にあったわけではありませんでした。
Stable Diffusionとほぼ同時期にリリースされたMidjourneyという画像生成も大きな注目を集めましたが、Midjourneyもコードは非公開となっていました。
一方で、Stable DiffusionはStability AI社からオープンソースで提供されており、そうした課金をするということをせずに無料で利用できます。(ChatGPTをイメージしてもらうと、よりイメージしやすいと思います。)
高いクオリティの画像を生成することができる
2つ目は、高いクオリティの画像を生成することができる点です。
Stable Diffusionは、訓練済みのAIモデルを搭載した画像生成AIであり、ユーザー自身が欲する画像のテキストを単語レベルで入力することで、様々な画像を入力することができます。
訓練済みモデルというのは言葉そのままの意味で、既に大量のデータを活用して学習が済んでいるAIモデルという意味です。
このモデルを活用することで、これまでの画像生成AIと比較してより効率的に入力されたテキストデータから生成すべき画像の推測ができるようになっています。
Stable Diffusionができること
技術レベルのみならず、様々な面での利活用が期待されているStable Diffusionですが、改めてどんなことができるのかをご紹介します。
Text To Image:テキストを入力することで新たな画像を生成
1つ目は、テキストを入力することで新たな画像を生成できることです。
入力するテキストは、通称「呪文(プロンプト、prompt)」と呼ばれており、プロンプトの入力のコツに関する記事や情報が非常に多く出回っております。
例えば「Cool man(かっこいい男性)」のようにテキストを入力するだけで、下記のような画像を生成することができます。
Image To Image:画像データを入力し新たな画像を生成
2つ目は、画像データを入力し新たな画像を生成できることです。
テキストのみではなく画像をサンプルデータとして使用することで、新しい画像を生成することも可能です。
加えて、テキスト or 画像という括りではなく、同時に併用した上で新しい画像を生成することも可能なので、生成したい画像について言語化しづらい際には、サンプル画像も入力データとして取り扱うことでさらにイメージに近い画像を生成できます。
拡張機能を活用することで、よりイメージに近い画像を生成
3つ目は、既存の画像を高解像度なものに再生成できることです。
Image To Imageで生成された画像について納得した仕上がりではなかった場合、例えば " Multi Diffusion " という拡張機能を活用することでより高解像度な画像へと再生成することが可能です。
" Multi Diffusion " とは、Image To Imageを用いて画像を生成する際に、画像のレイアウトを維持したまま、より高解像度な画像にすることができる機能です。
厳密には、それ以外でも高解像度化するための方法はあるのですが、そちらの詳細については別記事でご紹介できればと思います。ここでは「そんなこともできるんだな」といった程度で留めていただけたら幸いです。
Stable Diffuisionについてよくある質問
どうやって画像を生成するのか?
Stable Diffusionというのは、あくまでも画像を生成することができるAIの名称であり、ツールやシステムそのものを指しているわけではありません。
Stable Diffusionを使用したツールがあり、利用にあたってはそちらを使い、画像を生成する必要があります。
本記事でもこの後簡単にご紹介しますが、現在ではStabale Diffusionのモデルを使った画像生成のWebサービスやソフトが展開をされています。
初心者でも使えるのか?
ローカル環境にダウンロードして自分自身で環境構築をして使うという玄人向けのものもあれば、Webサービスでクラウド上で使えるものもあります。
特に後者のツールについては特別なことをする必要もなくそのままWeb上で利用でき、特別な知識がない方でも活用することは可能で、自分自身でコードを書かずともStabale Diffusionを活用した既存の画像生成ツールが、既にリリースされております。
イメージ通りの画像を生成するためのコツは?
3つ目は、イメージ通りの画像を生成するためのコツについてです。
これまでの質問と比較をするとやや応用的かつ実践的な質問になりますが、まずは基本的なルールを理解することが第一歩です。
もちろんそれ以外にも、本記事で既に登場している拡張機能を使うなど色々な手段があるのですが、まずはこうしたStabale Diffusionを使って画像生成するという新たなことにチャレンジされている方も多いことかと思いますので、ここでは基本的な内容だけ紹介します。
いくつかあるルールの中でも、特に重要なルールとしては、" 先に入力したプロンプトから優先して処理されること " です。
実は入力したテキストを平行処理しているのではなく、入力されたプロンプトの順番で画像生成の処理を行っています。(例:Cool man→①Cool②man の順番で処理しています。)
なので、こんな画像を生成したいというイメージがある際には、より重要視したい部分を前半部分に持ってくる等の工夫をすることで、イメージに近い画像を生成することができます。より詳しいコツについて知りたいかたは、こちらの記事をご覧ください。
Stable Diffusionの利用方法
Web版で提供されているサービスを利用する
1つ目は、Web版で提供されているサービスを利用する方法です。
先ほども記載しましたが、既にWeb上でStable Diffusionを活用したサービスはリリースされており、その種類も豊富にあります。
Hugging Faceで公開されているStable Diffusionを使用しているサービスもいくつかあります。
また、直近ではLINEの公式アカウントでもStable Diffusionを使って画像生成AIをお試しできるようなものもあります。
※Hugging Faceは、自然言語処理(NLP)のためのオープンソースプラットフォームで、モデルやデータ、トークン化、トレーニング、ファインチューニングなど、さまざまなNLP関連のタスクをサポートするツールやリソースを提供しているプラットフォームの名称です。こちらのプラットフォーム上でもStable Diffusionを活用したWebサービスが公開されています。
ローカル版のサービスをPCにインストールして利用する
2つ目は、ローカル版のサービスをPCにインストールして利用する方法です。
こちらについては、1点目の方法と比較をすると導入ハードルは少々高めとなっています。
ソースコードを利用して自分自身で環境構築をしなければならなかったり、使用してるPCのスペックもある程度高性能でなければ、画像生成に多くのメモリが割かれてしまい処理が遅くなったりしまうからです。
自分でソースコードを書いたり、環境構築をすることが得意な方や、チャレンジしてみたいという以外の方に関しては、ローカル環境ではなくWeb版で提供されているサービスのご利用をお勧めします。
Stable Diffusionを使用しているサービス
DreamStudio
DreamStudioは、Stability AI社が開発・運営する「Stable Diffusion」のオープンβ版として公開されたWeb上で利用できる画像生成ツールです。
基本的にできることはClipDropと近く、性能の高さも折り紙つきですが初回のユーザー登録で配布されるクレジットの分だけ無料で利用可能であり、以降は追加課金が発生します。
Clipdrop
ClipdropもStabilityAI社が提供するサービスで、Web上で誰もが簡単にStable Diffusionを使って画像を生成したり編集することができます。
Stable Diffusionを利用したWebツールはいくつかありますが、Stable Diffusionの生みの親であるStabilityAI社が提供しているという点と、無料にもかかわらずできることが多く生成される画像のクオリティが高いことから、特に評価の高いWebサービスと言われています。
プロンプト入力だけではなくネガティブプロンプトの入力も可能なので、より違和感のない高品質な画像を生成することができます。
※ネガティブプロンプト:出力してほしくない画像イメージを指示するためのテキストデータのことを指します
Stable Diffusion Online
Stable Diffusion OnlineもWeb上で利用できるツールですが、登録不要かつ完全無料で利用できます。
画像生成の速度についても申し分なく使用できますが、ネガティブプロンプトを入力するフォームがないので、生成された画像に対して違和感を感じることもあります。
Fotographer.ai
Fotographer.aiは弊社が提供しているサービスで、商品写真作成を生成AIの技術を活用して自動生成することができます。
サンプル画像をアップロードし、作成したい商品写真のイメージを入力もしくはテンプレートを選択するだけで、クリエイティブな商品写真を短時間で作成することが可能です。
DreamStudio、Clipdropの利用イメージ
DreamStudioの利用イメージ
実際にDreamStudioを使い、生成した画像はこちらです。
プロンプト:" Cool man with glasses infront of building "
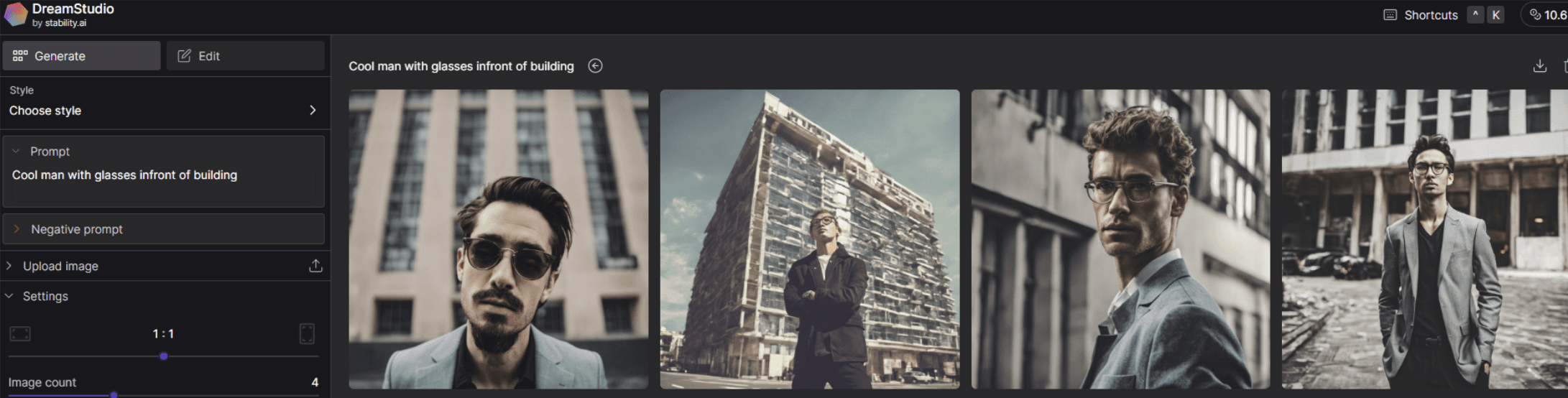
まさに指示した通りの画像を出力してくれました。
より具体的な操作方法について知りたい方は、こちらの記事をご覧ください。
Clipdropの利用イメージ
次に、Clipdropを活用して画像を生成してみます。

先ほどと同じプロンプトで生成してみました。
ともに指示した通りの画像を生成してくれています。
より具体的な操作方法については、こちらの記事をご覧ください。
Stable Diffusionの活用例
ブランドロゴの作成
1つ目は、ブランドロゴの作成です。
ロゴの形はもちろんのこと、レイアウトやそもそものアイディア出しの段階に悩んでいる場合でも、Stable Diffusionを使って複数のパターンを出力することで、強力なサポート役を任せることができます。
うまく使いこなせるようになれば、専門のデザイナーに依頼するコストや手間を省けることが期待できます。
建物の外装/内装のイメージ画像の作成
2つ目は、建物の外装/内装のイメージ画像の作成です。
建造物の外観もそうですが、内部の装飾や家具、インテリアなどもイメージ画像として出力が可能です。
外観だけではなく内装の詳細な部分までを画像としてイメージできることで、物件を新しく探す場合や、自宅を新築、或いはリフォームする場合に希望のイメージを相手に視覚的に伝えられるようになるなど、営業サポートのツールとしての活躍も期待できます。
新製品のアイディア画像の作成
3つ目は、新製品のアイディア画像の作成です。
新製品を作成する際に、どんな製品を作成したら良いのかといったことや、どんなデザインにすべきかというのは非常に難しい課題だと思います。
Stable Diffusionを活用すれば、テキストデータからイメージ画像を生成できるので、サポート役として活用できる可能性が大いにあると思います。
クリエイティブなインスピレーションの享受
4つ目は、クリエイティブなインスピレーションを享受できることです。
例えば、広告物のデザインに悩んだりしている際には、Stable Diffusionを活用し、自身の頭の中にある情報をテキストとしてインプットすることでヒントを得られたりすることにも活用できます。
以上はあくまでもほんの一例なので、他にどんなことができるのかを利用される中で見つけ、自分自身のパフォーマンスはもちろんのこと、組織としてのパフォーマンス向上にもつなげていってみてはいかがでしょうか。
Stable Diffusionで生成された画像を利用する際の注意点
今後期待される活躍の期待値のみならず、既に現時点で価値を発揮しているStable Diffusionですが、利用する上での注意点がいくつかあります。
商用利用が認められていない画像を使用した場合
1つ目は、商用利用が認められていない画像を使用した場合です。
Image To Imageを使った場合、著作権を侵害するとして商用利用が認められない可能性があるので注意が必要です。
例えば、他社が既に公開しているロゴや人物をダウンロードし、Image To Imageを使って画像を生成した場合、サンプルデータとして使用したロゴの制作者から著作権を侵害したとして、訴えられるリスクがあります。
そのため、Image To Imageで生成された画像を商用利用として使う場合、そもそも使用した画像がフリー素材なのか、誰かの所有権(著作権)があるのかどうかの確認をして頂くことをお勧めします。
商用利用の認められていないモデルを追加学習させた場合
2つ目は、商用利用の認められていないモデルを追加学習させた場合です。
こちらはWeb版ではなくローカル版で利用する場合によく取られる手法なのですが、Stable Diffusionは先に述べたように既に訓練済みのモデルなのですが、実は他のモデルを追加学習させることでより精度の高い画像を生成できるようになります。
モデルとは特定の要素に特化したデータのことを指し、例えばアニメ調のモデルを使って追加学習させれば、よりクオリティの高いアニメ風の画像を生成することが可能です。
非常に利便性の高い手法ですが、商用利用が目的でモデルを追加で学習させる場合、そのモデルそのものが商用利用可能かどうかを事前に確認してください。
商用利用が認められていないモデルを使用し、利益を得た場合、モデルの権利者などが法的措置を講じる可能性があるからです。
まとめ
Stable Diffusionの概要から、基本的な利用方法、利用上の注意点などについてご紹介しました。
生成AIを活用して画像を作成するという新しい取り組みに対して、何かしらの不安や恐れを感じてたりわからないことが多いと感じられる方もいらっしゃるかと思います。そうした方々にとって、本記事が生成AIや画像生成AIの理解を進める一助になりましたら幸いです。


