Stable Diffusionの使い方をDreamStudio、Clipdropを例に解説!

Fotographer AI, Inc.
Latest Update :
September 20, 2023


生成AIの登場によって、ますますAIが大きな着目を浴びてきている中で、徐々に生成AIについての理解を深めたり、実際に使ってみた方も多いのではないでしょうか?
世間的にはChatGPTが注目株かと思いますが、それと同じくらい反響を呼んでいるのが画像生成AIであり、今回ご紹介するStable Diffusionは、まさに画像生成AIの代表格です。
本記事では、Stable Diffusionを実際に利用する方法についてお話しします。
Stable Diffusionとは
Stable DiffusionとはStability AI社が開発した画像生成AIです。
画像生成AIの中だと、比較的後発でありながらモデルそのものが有するポテンシャルの高さや、オープンソースであるがゆえに誰もがAIを使って画像生成をできるようになった点から、画像生成AIの風雲児のようにも呼ばれています。
生成された画像を高解像度にするといったことや、その他の拡張機能が豊富にあったりすることから、今後より多くの場面で活躍が期待されています。
より詳細な内容について知りたい場合は、こちらの記事をご覧ください。
Stable Diffusionの利用方法
Stable Diffusionを利用するには、大きく分けて次の2つの方法があります。
Web上で使えるツールを利用する
1つ目は、Web上で使えるツールを利用する方法です。
特別何かのソフトやシステムをDLすることなく使えるので、お手軽に利用できる点がメリットです。しかし、生成した画像の枚数が一定以上に達すると課金を行う必要があったり、無料だとお試し版のような形でしか利用できない点はデメリットといえます。
デザイナーが本職の方で本格的にStable Diffusionを利用してやっていきたいという方には少々物足りないかもしれませんが、初めて利用される方で試しに使ってみたいという方には十分でしょう。
ローカル版のツールをPCにダウンロードして利用する
2つ目は、ローカル版のツールをPCにダウンロードして利用する方法です。
先ほどのWeb上で使えるツールと比較をすると、自分の好きなようにカスタマイズできたり際限なく無料で利用できるという点がメリットです。
一方で、デメリットとしてはご自身でPCにインストールして、公開されているソースコードをもとに環境を構築しなければならなかったり、画像を効率よく生成するためにPCのスペックが一定以上求められるなど、導入ハードルがやや高いことがデメリットです。
本格的にStable Diffusionを使っていきたいという方には、おすすめです。
Stable Diffusionの導入方法
さて、ここから先は実際にStable Diffusionを実践するための方法と各STEPについて、簡単に記載していきます。
Stable Diffusionを活用するために必要なPCのスペックについて
まず、必要なスペックですがWeb版については、特に指定がなく、Web上でテキスト(画像)を入力するだけで画像が生成されます。
使用されているネット環境の速度が著しく遅かったり、PCの動作が重すぎる等の問題がなければ問題なく利用できます。
一方で、ローカル版を利用される際には次のスペックが推奨とされています。(記事公開時点)
・PCのタイプ:デスクトップ型
・メモリ:16㎇以上(学習させる場合は32GB)
・OS:Windows(64bit)
・CPU:特に気にしなくて問題ない
・GPU:VRAM12GB~
・ストレージ:512GB~(可能なら1TB以上の空き)
やはり一定以上のスペックが求められますが、Web版と違いWeb上ではなく、PCが実際にソースコードを読み込んで画像を生成するプロセスが発生するので、ローカル版での利用をご検討の方は、こちらの推奨環境を揃えた上で利用されることをお勧めします。
Web版で利用できるStable Diffusionを使って、画像を生成できるツール
Web版で利用できるツールについてはいくつか種類がありますが、今回はその中でも、DreamStudioとClipDropというツールを使って実践してみます。
その他にも様々なツールがありますので、他のものも気になるという方はぜひこちらの記事をご覧ください。
DreamStudio、Clipdropを利用するための3STEP、簡単な操作方法について
それではさっそく、DreamStudioとClipdropを利用するまでの手順と、操作方法について解説していきます。
DreamStudioを利用するための3STEP
STEP1. こちらのリンクをクリック
STEP2. アカウントを作成 or Googleアカウントをお持ちの方は「Continue with Google」を押してそのままログイン
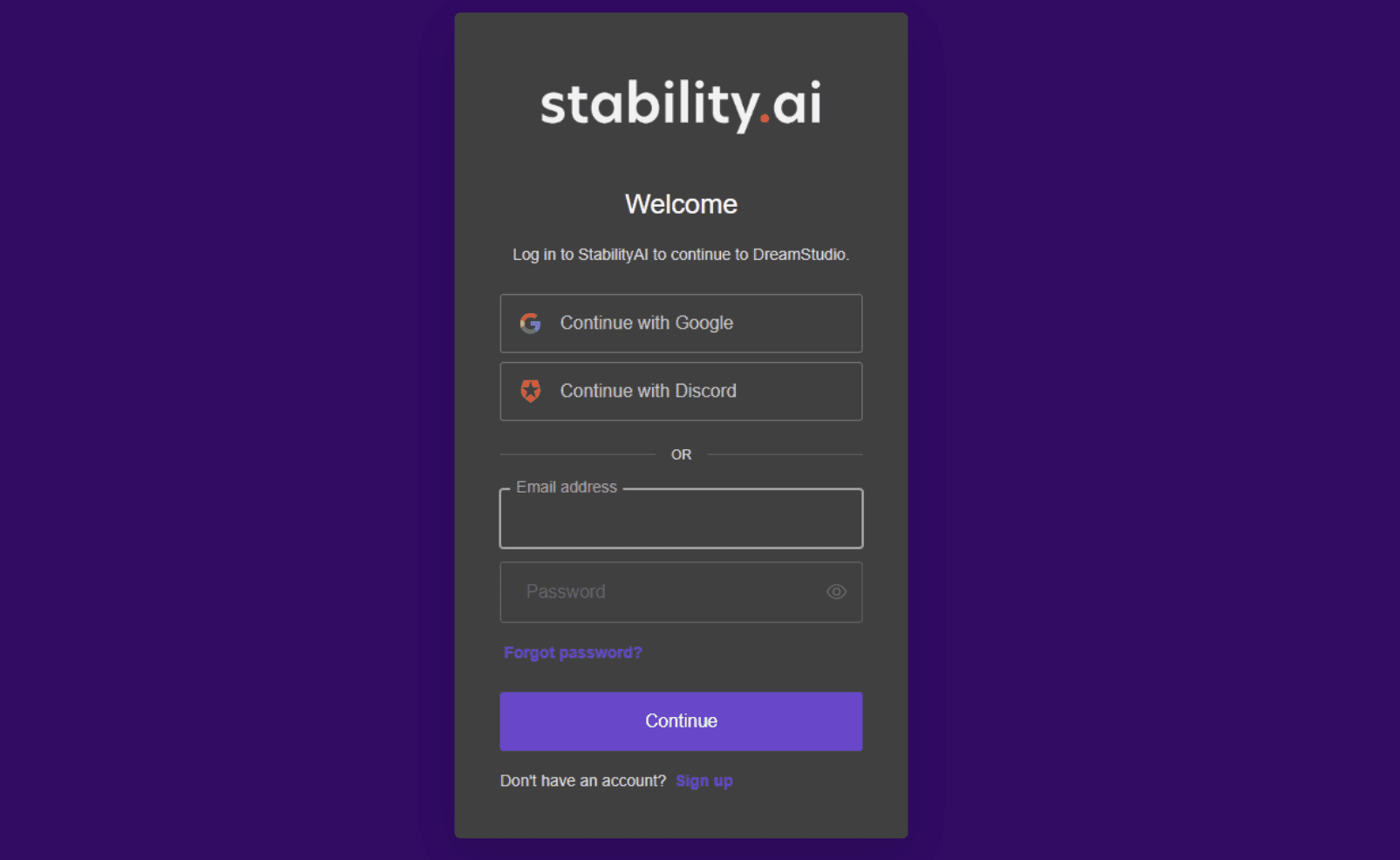
STEP3. 画像のような画面まで行き着いたら完了です
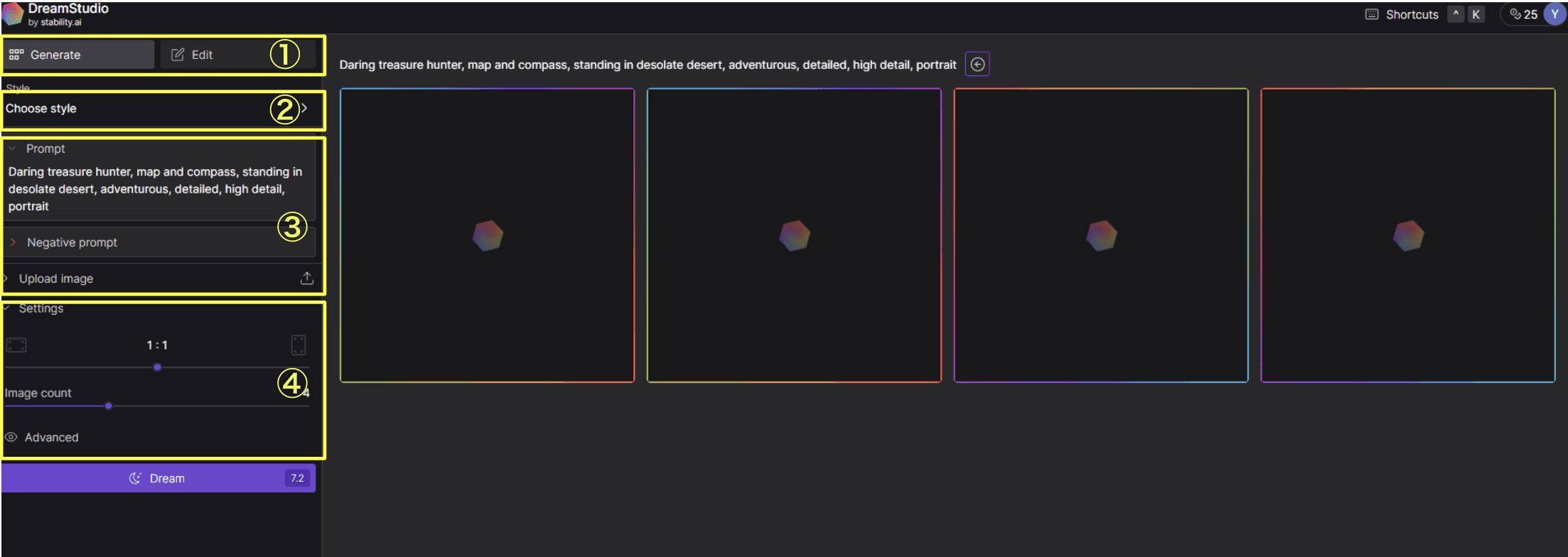
DreamStudioの簡単な操作方法について
次に、簡単に操作する画面と、画像を生成する基本的な方法について記載します。
①:単に画像を生成するモード(Generate)か、生成した上で編集する(Edit)のモードを選択することができます。
②:出力される画像の画風(Style)を選択できます。
③:画像を生成するにあたって、プロンプト(prompt)、ネガティブプロント(Negative prompt)を入力、画像をアップロードできます。
④:画像の横縦比や、生成される画像の枚数を調整できます。
下記は、私が打ち込んだプロンプトをもとに生成された画像です。
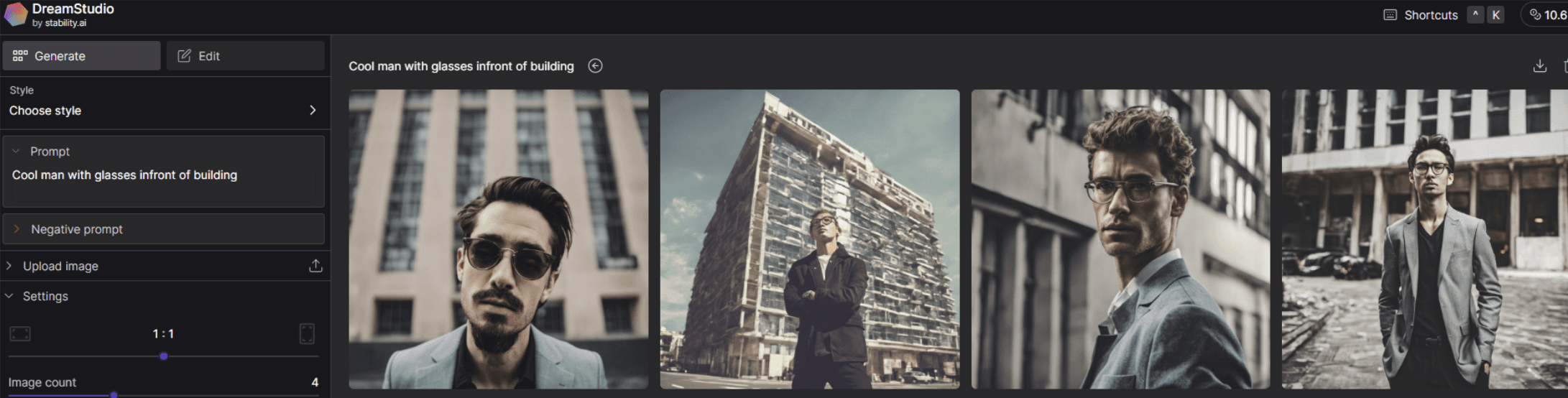
いかがでしょうか。指示したプロンプトは「cool man with glasses infront of building(ビルの前にたたずむ、眼鏡をかけたかっこいい男性)」というものですが、違和感の少ない画像を出力することができました。
Clipdropを利用するための3STEP
STEP1. こちらのリンクをクリック
STEP2. 下に少しスクロールして、" STABLE DIFFUSION XL"のボタンをクリック
STEP3. 画像のような画面まで行き着いたら完了です
Clipdropの簡単な操作方法について
画面緑色枠の中にプロンプトを打ち込み、Generateのボタンを押すだけで、画像が生成されます。
また、①を押すと画風やアスペクト比の設定をするためのメニューが表示されます。ネガティブプロンプトの設定も可能です。
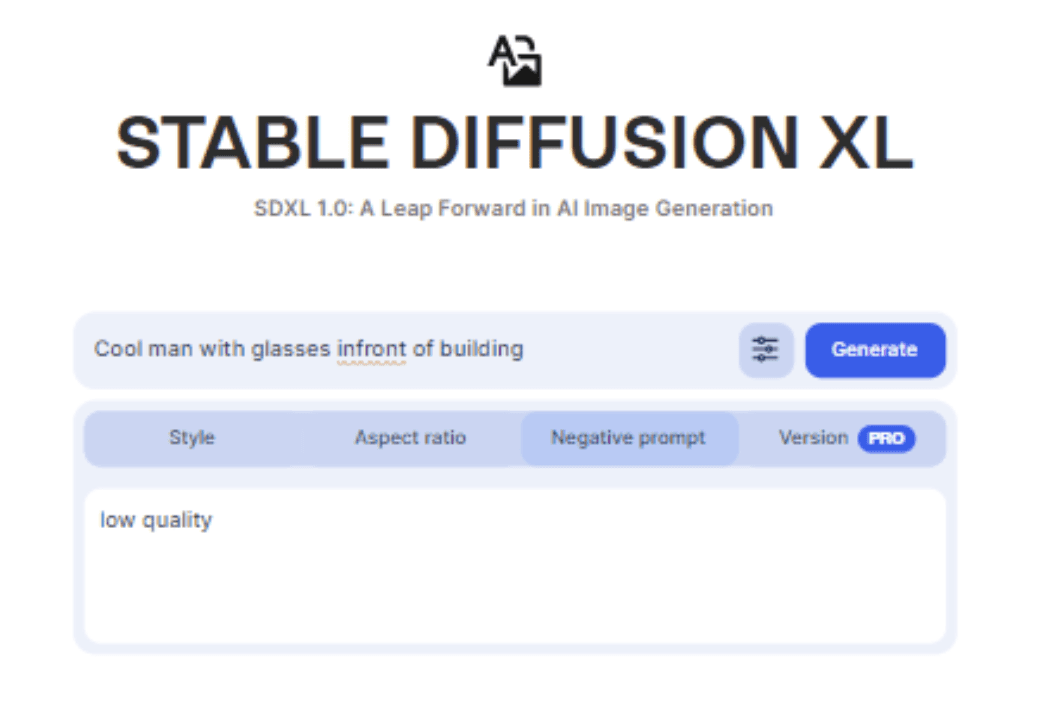
今回は、先ほどと同じプロンプトに加え、ネガティブプロンプトとして " low quality " を入れて生成してみます。

こちらも意図したものに近い画像が生成されました。ネガティブプロンプトなども活用し、より思い通りの画像を生成できるよう色々試されてみてはいかがでしょうか。
※ネガティブプロンプト:出力してほしくない画像イメージを指示するためのテキストデータのことを指します
Stable Diffusionを用いて画像生成する際によく聞く単語集
ここまでのところで、Stable Diffusionを使って画像生成をする準備は整ったかと思います。ここでは、各ツールを利用していく上でよく目にする言葉を改めて紹介していきます。
プロンプト(呪文)
どのような画像を生成するかを指示するためのテキストです.
生成AIを活用していく上では最も基本的な用語といえます。
ネガティブプロンプト(反対呪文)
生成される画像に、反映したくない要素を指定するためのテキストです。
例えばネガティブプロンプトに「worst quality」と入れると、低品質な画像が生成されるのを防ぐことができます。
CFG(Classifier-Free Guidance)スケール
画像を生成する際に、どの程度プロンプトを反映して画像を作成するのかを決める値です。
大きければ大きいほどプロンプト通りの画像を生成するようになりますが、大きすぎると違和感のある画像が生成されることがあります。
ステップ数
ノイズ除去の繰り返し数のことを指します。
値が大きければ大きいほど、画像がより具体的になる傾向がありますが、その分処理に時間がかかってしまうため、画像を生成するまでに時間がかかってしまいます。
また、同時に画像全体が崩壊してしまうこともあるため、小さすぎても大きすぎてもNGです。
ここより下は、中上級者の方向けの内容になります。
VAE
VAEとは生成する画像のクオリティを向上させるためのファイルです。
特に配色やデザインが細かな画像を生成したい際には重要で、これがないと違和感のある画像になる場合があります。
一方で、モデルによっては予めVAEが組み込まれており、別途VAEをダウンロードする必要がないものもあるので事前に調べられることをお勧めします。
マージ
モデル同士を合体させて新たなモデルを作ることを指し、合体させたモデルはマージモデルと呼ばれます。
ControlNet
画像生成において、被写体のポーズを指定できる技術です。
ポーズ以外にも色々な応用が利くので非常に利便性の高い技術です。
LoRA(Low-Rank Adaptation)
既存のモデルに新しい被写体を学習させる追加学習の手法の一つです(または、この手法によって作成したモデルを指す場合もあります)。
通常のText To Imageだと特定のキャラクターや画風・シチュエーション等を決め打ちで出すことはハードルが高いのですが、LoRAで予め学習させておけば欲しい画像を生成しやすくなります。
比較的性能が低いグラフィックボードでも学習を行えたり、出力されるモデルが軽量であったりすることから主流の追加学習法となっています。
Stable Diffusionで効果的にプロンプト・ネガティブプロンプトを利用するコツ
もう少し実践的な知識として、プロンプト・ネガティブプロンプトを利用するコツについて解説します。
AIがプロンプトを読み込む際の基本的な仕様を知る
いくつかあるルールの中でも、特に重要なルールとしては、先に入力したプロンプトから優先して処理されることでしょう。
実は入力したテキストを平行処理しているのではなく、入力されたプロンプトの順番で画像生成の処理を行っています。
なので、こんな画像を生成したいというイメージがある際には、より重要視したい部分を前半部分に持ってくる等の工夫が大切です。
プロンプトで指示を出せる範囲について理解する
プロンプトで指示を出せる範囲についても理解すると、より効率的に、かつ高品質な画像を生成することができます。
Stable Diffusionでは、以下のような項目についてプロンプト/ネガティブプロンプトで指定をすることができます。
※こちらはほんの一例です。
・品質
・背景
・人種、年齢、表情、状態、状況等の基本情報
・色、時間、光の当たり方、体の各種パーツや髪型、服装等の追加情報
・人種、年齢
・画風
・構図
Stable Diffusionでより高精度な画像を出力したい場合
ここまでのところで、一定以上の画像を生成できるようになっているかと思いますがさらに高精度な画像を出力したいという方向けにご紹介します。
理想の画像が出力されるまで、さまざまなプロンプトや画像を読み込ませてみる
1つ目は、とにかく試行回数を重ね、学習をさせていくことです。
たとえ同じ単語であったとしても、先に記載したようにその順番によって生成されるイメージは異なってきます。
画像というクリエイティブであるからこそ、それぞれの方々が感じるフィーリングも非常に重要かと思いますので、ぜひイメージ通りの画像が生成されるまで試されてみることをオススメします。
ControlNetや、LoRA等の技術を活用する
2つ目は、ControlNetや、LoRA等の技術を活用してみることです。
Stable Diffusionが世間で高い評価を受けている背景として、まさにこうした拡張機能やできることの豊富さといったことが挙げられます。
特にLoRAに関しては、比較的性能が低いグラボで学習を行えたり、出力されるモデルが非常に軽量であったりすることから現在主流の追加学習法となっていますので、ぜひお試し頂きたいです。
まとめ
本記事では、Stable Diffusionが提供しているDreamStudio、Clipdropを使って実際に画像生成をしてみましたいかがでしたでしょうか。
今回紹介した内容は、Stable Diffusionができることの一部にすぎず、今後さらに様々なことができるようになっていくことかと思います。本記事がStable Diffusionの活用をお考えの方の参考になりましたら幸いです。


